
Advanced Concepts of Modeling in AI Class 10 (CBSE 417) help students understand how AI models are trained, tested, and improved. Based on the CBSE curriculum, this topic covers model evaluation, accuracy, overfitting, and performance metrics, enabling students to build a deeper understanding of how intelligent systems make reliable predictions.
| Board | CBSE |
| Textbook | Code 417 |
| Class | 10 |
| Chapter | 2 |
| Chapter Name | Advanced Concepts of Modeling in AI |
| Subject | Artificial Intelligence 417 |
Advanced Concepts of Modeling in AI Lecture
Revisiting AI, ML, DL
Artificial Intelligence is the umbrella terminology which covers machine and deep learning
Under AI it covers Machine Learning and Deep Learning comes under Machine Learning. It is a funnel type approach where there are a lot of applications of AI out of which few are those which come under ML out of which very few go into DL.
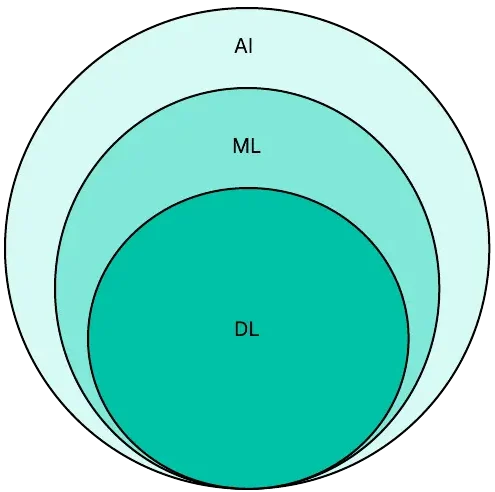
Artificial Intelligence (AI)
AI refers to any technique that enables computers to mimic human intelligence. An artificially intelligent machine works on algorithms and data fed to it and gives the desired output.
An artificially intelligent machine works on algorithms and data fed to it and gives the desired output.
Machine Learning (ML)
ML enables machines to improve at tasks with experience. The machine here learns from the new data fed to it while testing and uses it for the next iteration. It also takes into account the times when it went wrong and considers the exceptions too.

This is just a broad representation of how a machine learning model works. Input (past or historical data) is given to the ML model and the model generates output by learning from the input data.
Examples of Machine Learning (ML)
Object Classification
Identifies and labels objects present within an image or data point. It determines the category an object belongs to.
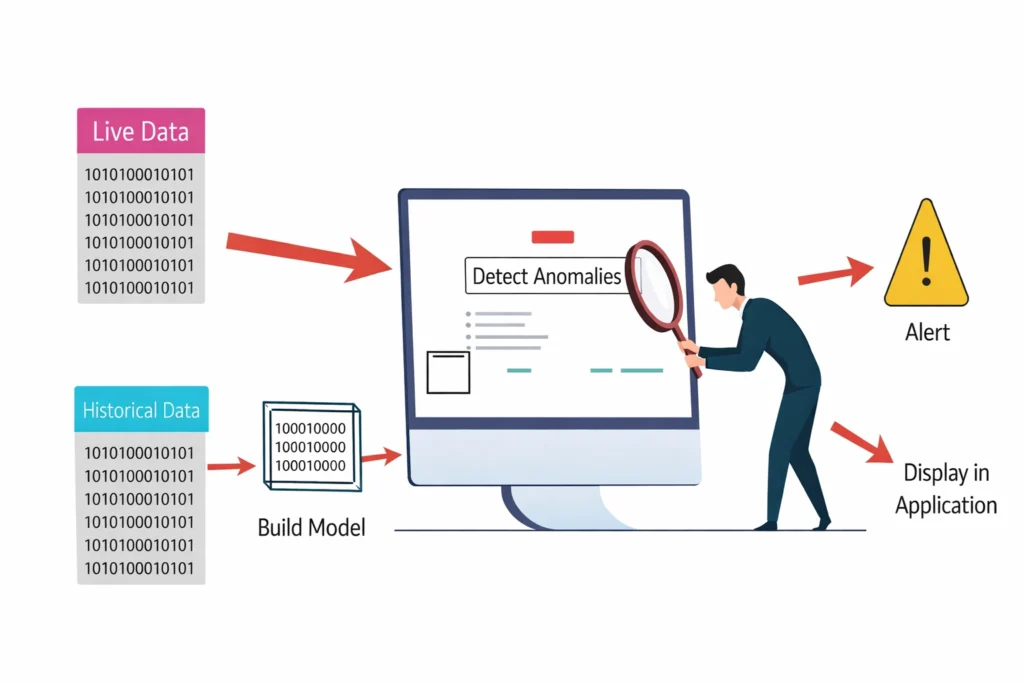
Anomaly Detection
Anomaly detection helps us find the unexpected things hiding in our data. For example, tracking your heart rate, and finding a sudden spike could be an anomaly, flagging a potential issue.
Deep Learning (DL)
DL enables software to train itself to perform tasks with vast amounts of data
- In deep learning, the machine is trained with huge amounts of data which helps it into training itself around the data.
- Such machines are intelligent enough to develop algorithms for themselves.
- Deep Learning is the most advanced form of Artificial Intelligence out of these three.
Examples of Deep Learning (DL)
Object Identification
Object classification in deep learning tackles the task of identifying and labeling objects within an image. It essentially uses powerful algorithms to figure out what’s in a picture and categorize those things
Digit Recognition
Digit recognition in deep learning tackles the challenge of training computers to identify handwritten digits (0-9) within images.

Common terminologies used with data
Data
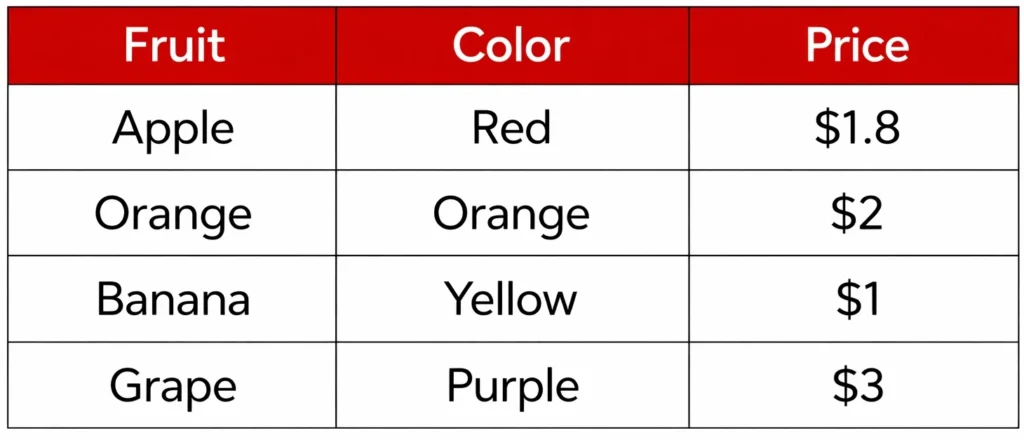
- Data is information in any form
- For e.g. A table with information about fruits is data
- Each row will contain information about different fruits
- Each fruit is described by certain features
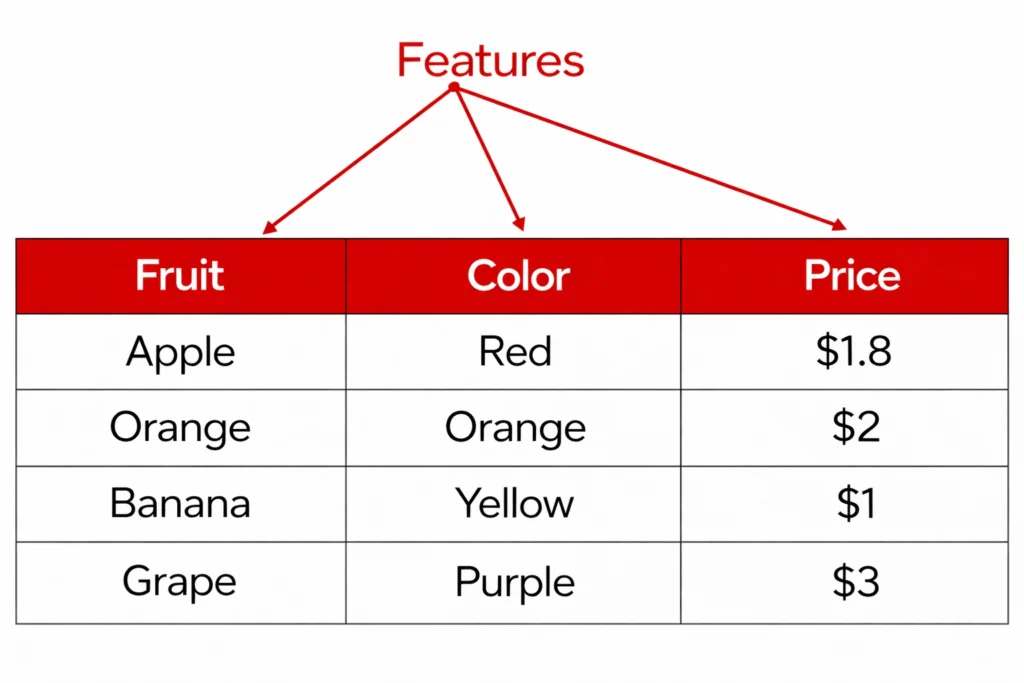
Features
- Columns of the tables are called features
- In the fruit dataset example, features may be name, color, size, etc.
- Some features are special, they are called labels
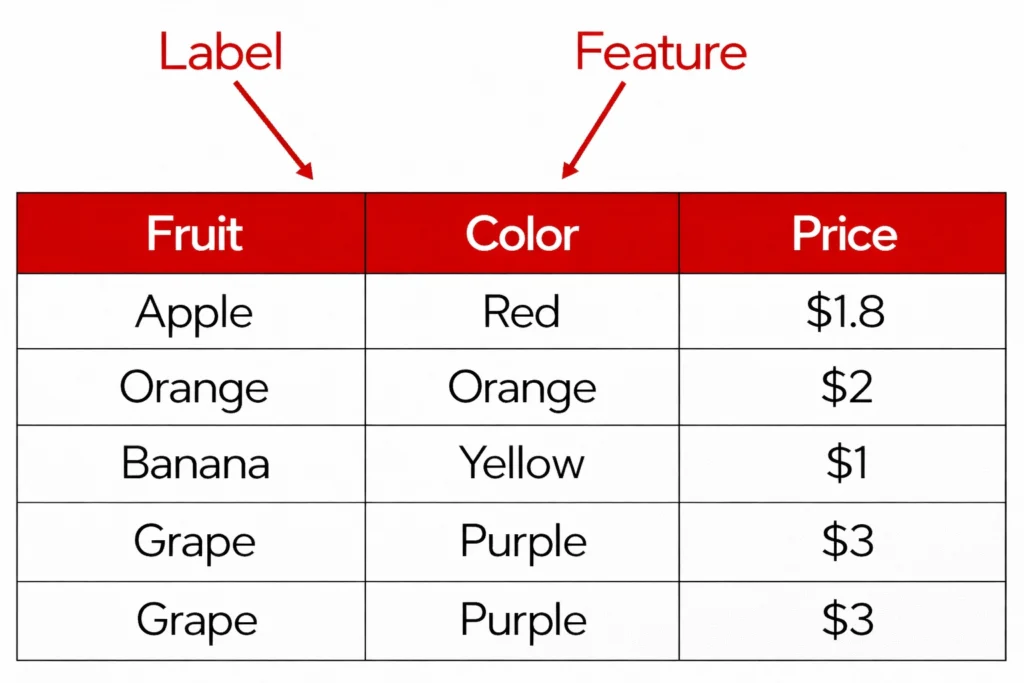
Labels
- Data labelling is the process of attaching meaning to data
- It depends on the context of the problem we are trying to solve
- For e.g. if we are trying to predict what fruit it is based on the color of the fruit, then color is the feature, and fruit name is the label.
- Data can be of two types – Labelled and Unlabeled
Labeled Data
Data to which some tag/label is attached.
For e.g. Name, type, number, etc.
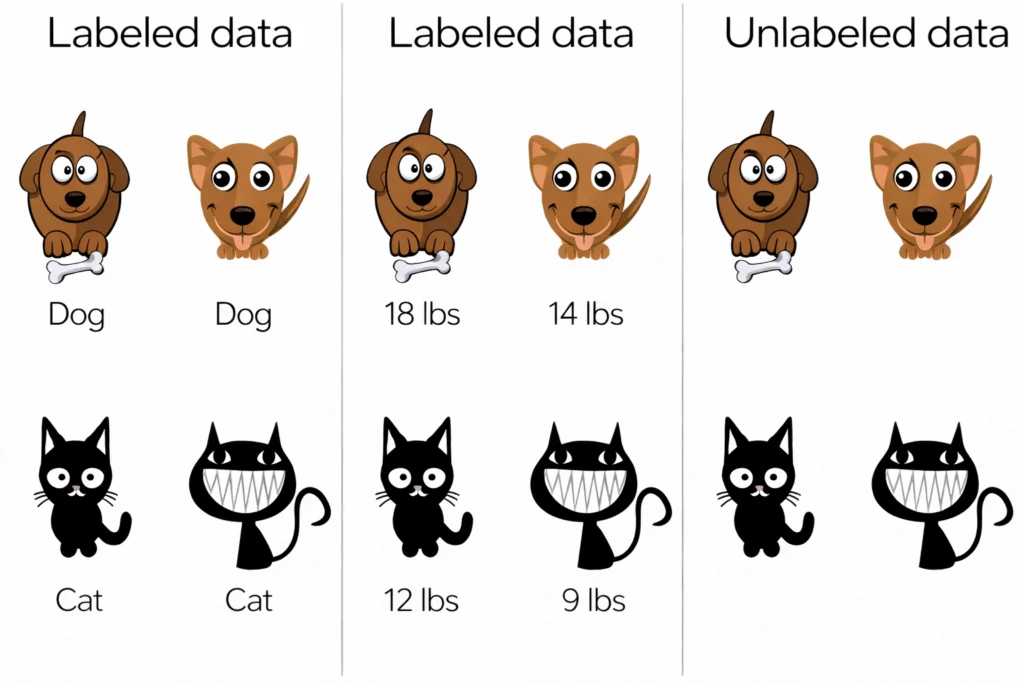
Unlabeled Data
The raw form of data
Data to which no tag is attached.
Training Data
- The training data set is a collection of examples given to the model to analyze and learn.
- Just like how a teacher teaches a topic to the class through a lot of examples and illustrations.
- Similarly, a set of labeled data is used to train the AI model.
Testing Data
- The testing data set is used to test the accuracy of the model.
- Just like how a teacher takes a class test related to a topic to evaluate the understanding level of students.
- Test is performed without labeled data and then verify results with labels.
Modelling
AI Modelling refers to developing algorithms, also called models which can be trained to get intelligent outputs. That is, writing codes to make a machine artificially intelligent.
- In general, there are two approaches taken by researchers when building AI models. They either take a rule-based approach or a learning approach.
- A Rule based approach is generally based on the data and rules fed to the machine, where the machine reacts accordingly to deliver the desired output.
- Under the learning approach, the machine is fed with data and the desired output to which the machine designs its own algorithm (or set of rules) to match the data to the desired output fed into the machine
Types of AI Models
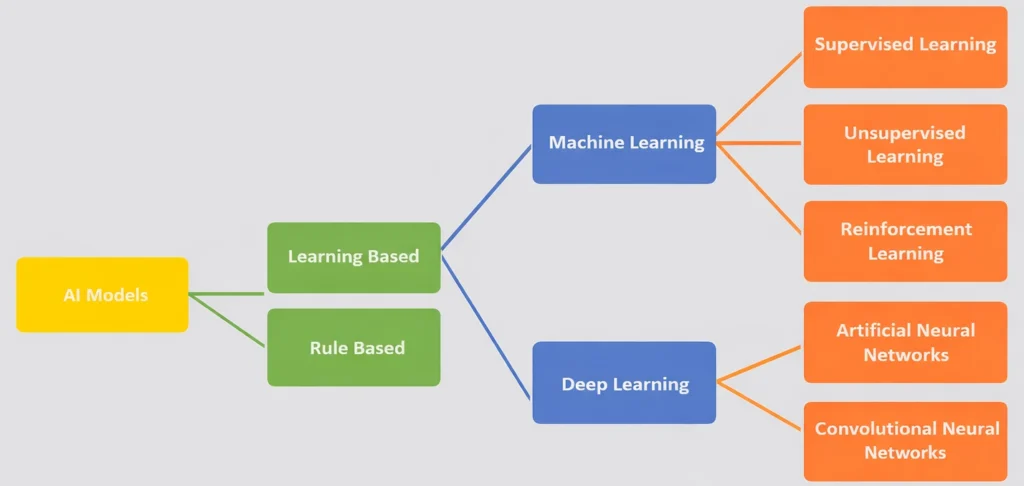
Rule Based Approach
The machine follows the rules or instructions mentioned by the developer, and performs its task accordingly
Rule Based Approach refers to the AI modelling where the relationship or patterns in data are defined by the developer.

Example: Rule-based Chatbots are commonly used on websites to answer frequently asked questions (FAQs) or provide basic customer support.
Learning Based Approach
A computer learns how to do something by looking at examples or getting feedback, similar to how we learn from experience.
Instead of being explicitly programmed for a task, the computer learns to perform it by analyzing data and finding patterns or rules on its own.

Rule-based AI makes Fixed models (cannot adapt to changes),
Learning-based AI makes Flexible models (can adapt to changes)
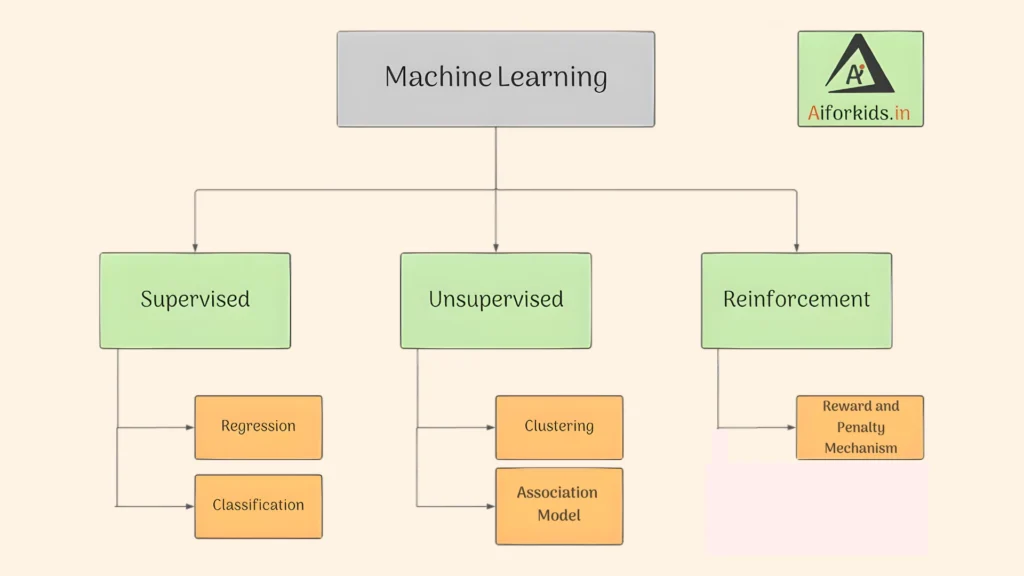
Types of Learning Models
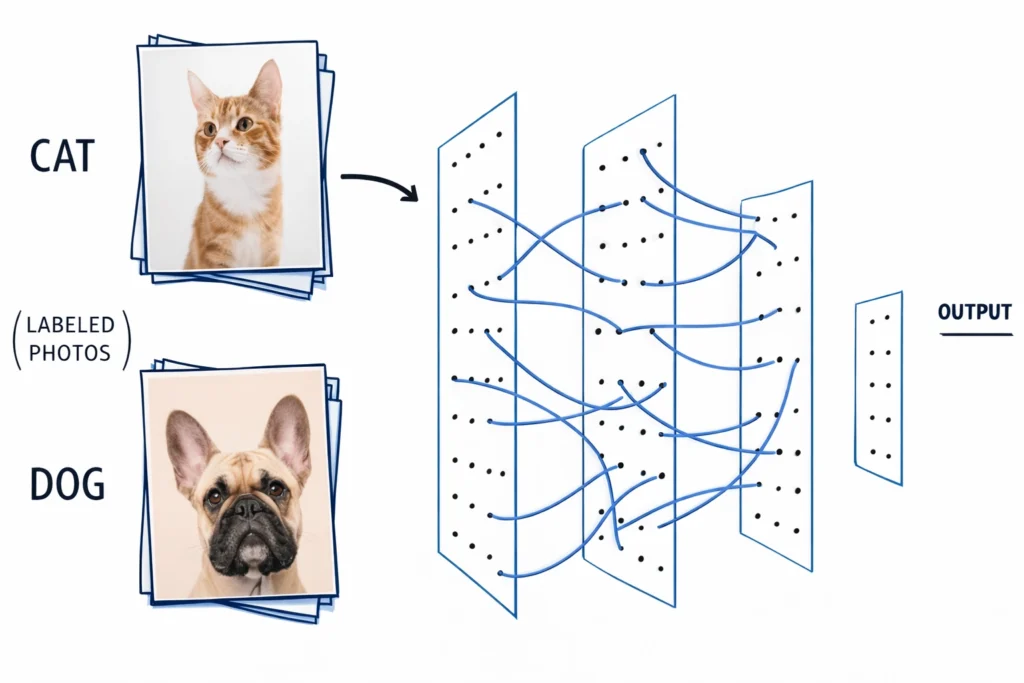
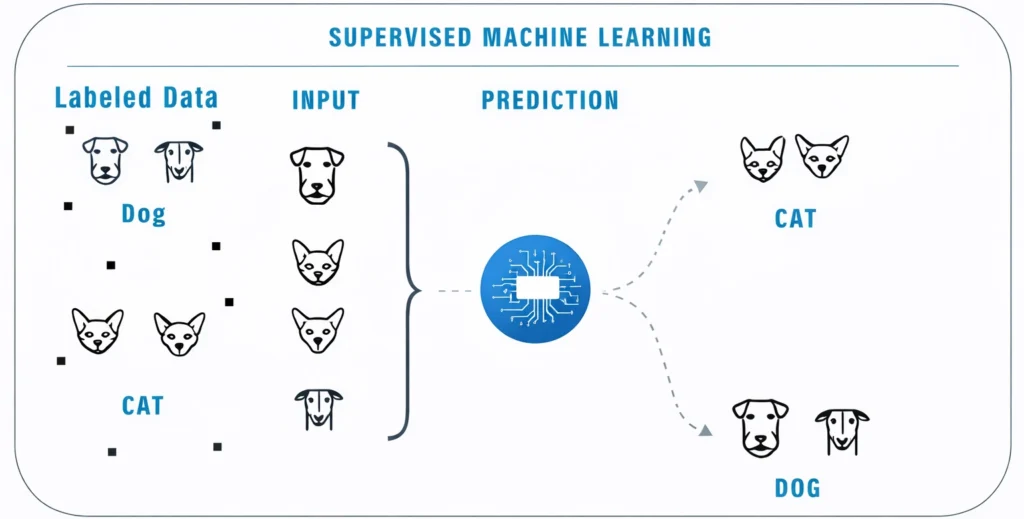
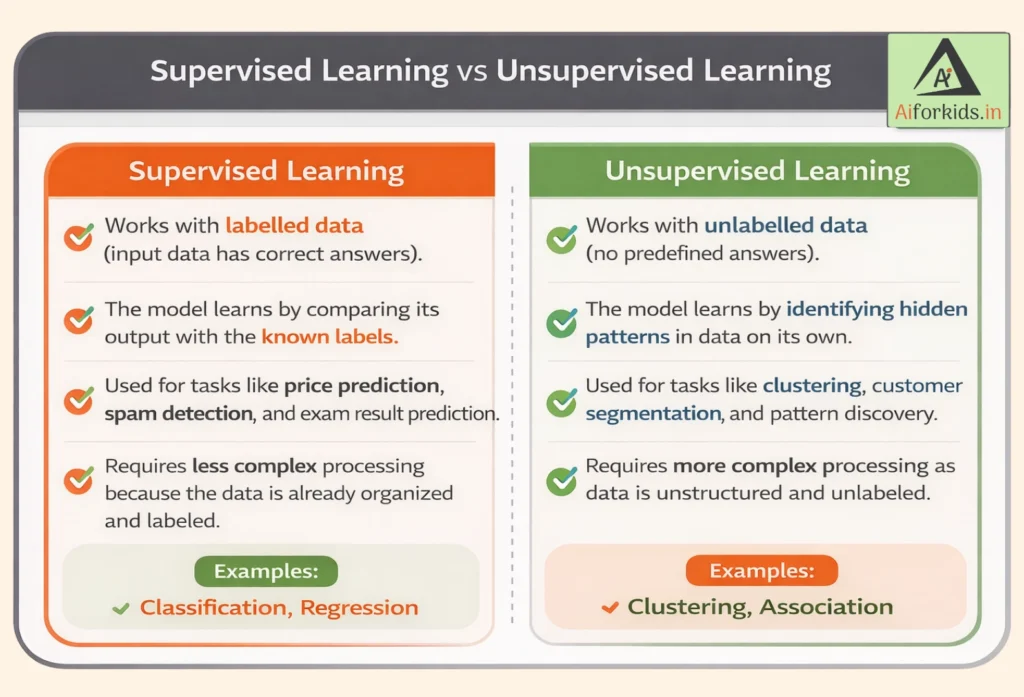
Supervised Learning
In a supervised learning model, the dataset which is fed to the machine is labelled.
In other words, we can say that the dataset is known to the person who is training the machine only then he/she is able to label the data.
Supervised Learning indicates having a supervisor as a teacher or similarly, supervised learning is when you make the machine learn by teaching or training the machine using labeled data.
Example:the model has learned from labeled input data and produces output to classify them as dogs and cats.
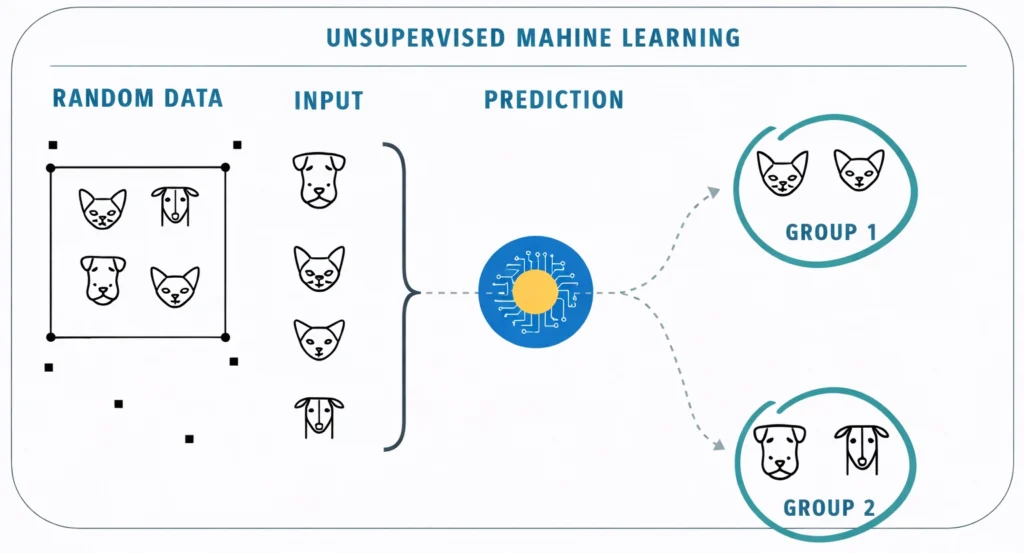
Unsupervised Learning
An unsupervised learning model works on unlabelled dataset. The unsupervised learning models are used to identify relationships, patterns and trends out of the data which is fed into it.
Example:the model has learned from labeled input data and produces output to classify them as dogs and cats.
This means that the data which is fed to the machine is random and there is a possibility that the person who is training the model does not have any information regarding it. It helps the user in understanding what the data is about and what are the major features identified by the machine in it.
The machine is responsible to discover patterns, similarities, and differences on its own based on the unlabeled dataset
Example: As you observe in the image, input is not labeled but
the model can come up with two clusters by identifying similar patterns and attributes and have grouped them together
- All Cats have been grouped into cluster 1
- All Dogs have been grouped into cluster 2
Supervised V/S Unsupervised Learning
Reinforcement Learning
This learning approach enables the computer to make a series of decisions that maximise a reward metric for the task without human intervention and without being explicitly programmed to achieve the task.
Reinforcement learning is a type of learning in which a machine learns to perform a task through a repeated trial-and-error method.
Example:
- Let’s say you provide an image of an apple to the machine and ask the machine to predict it.
- The machine first predicts it as ‘cherry’ and you give negative feedback that it’s incorrect.
- Now, the machine learns that it’s not a cherry
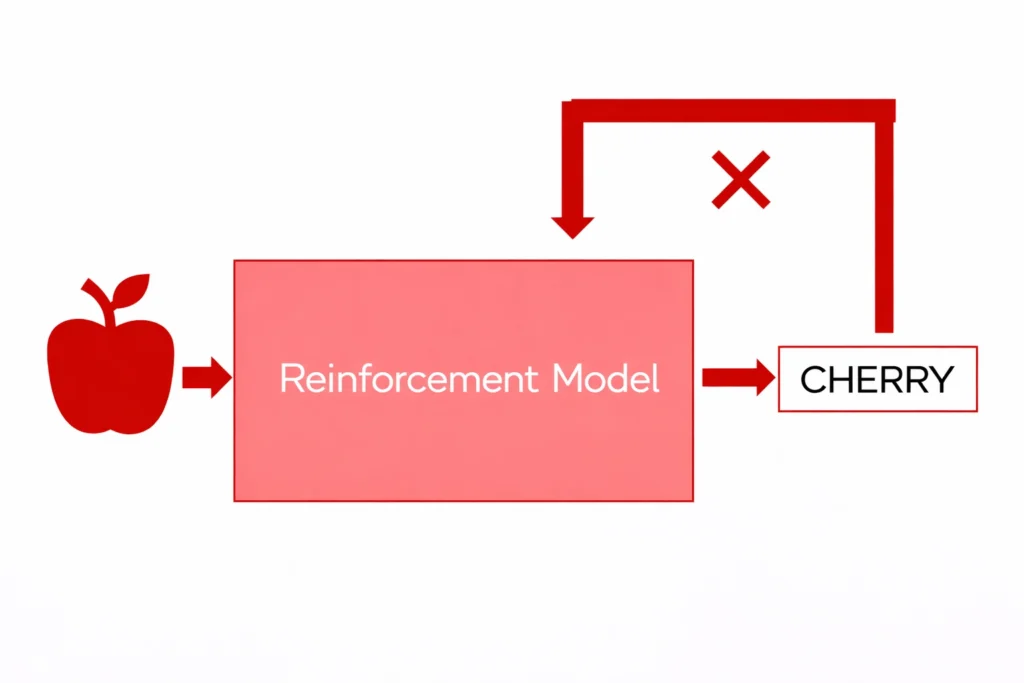
Example: Let’s say you provide an image of an apple to the machine and ask the machine to predict it.
The machine first predicts it as ‘cherry’ and you give negative feedback that it’s incorrect.
Now, the machine learns that it’s not a cherry
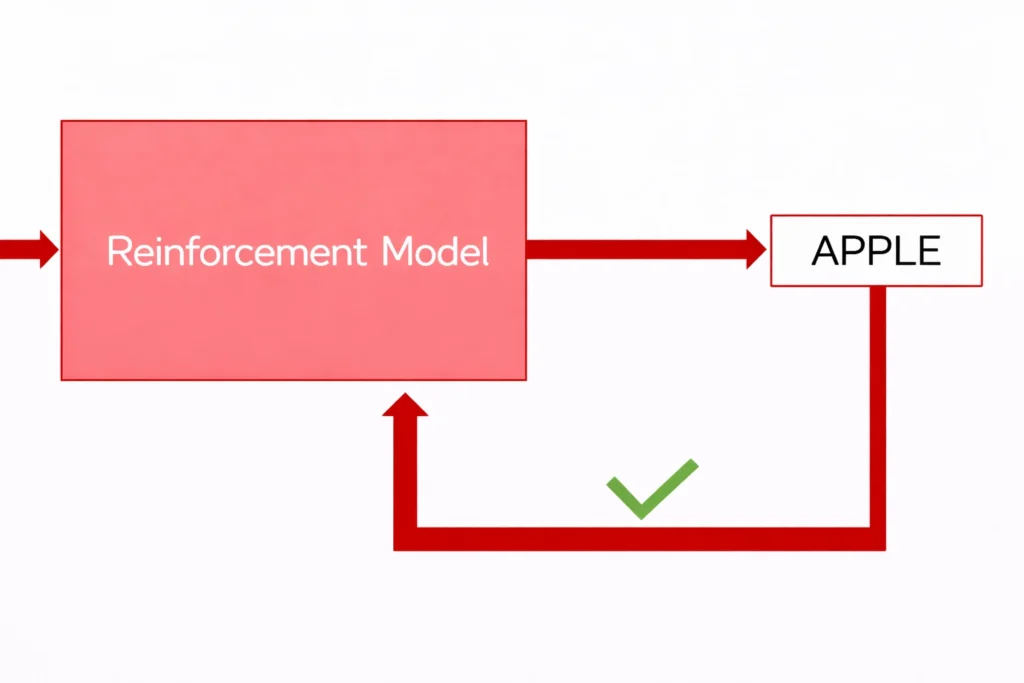
- Then again, you ask the machine to predict the fruit by giving an image of an apple as input:
- Now, it knows it is not a cherry.
- It predicts it as an apple and you give positive feedback that it’s correct.
- So, now the machine learns that this is an apple.
Summary of ML Models
- Supervised learning models are used when we want to determine relationships through training
- Unsupervised learning models are used when we want to discover new patterns from data.
- Reinforcement learning models are used when we want to implement machine learning through a reward mechanism.
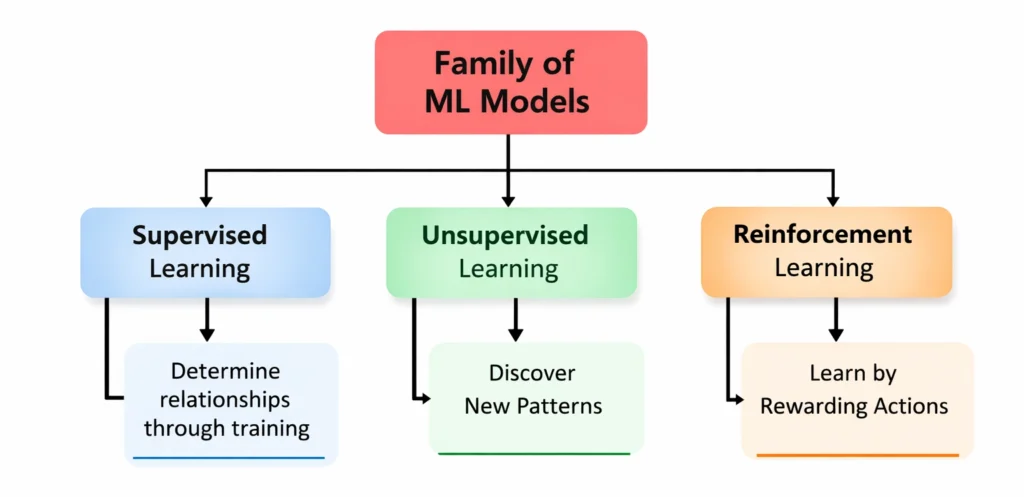
Sub-categories of Supervised Learning Model
There are two types of Supervised Learning models: Classification model and Regression model.

Classification Model
Data is classified according to the labels.
This model works on discrete dataset which means the data need not be continuous.
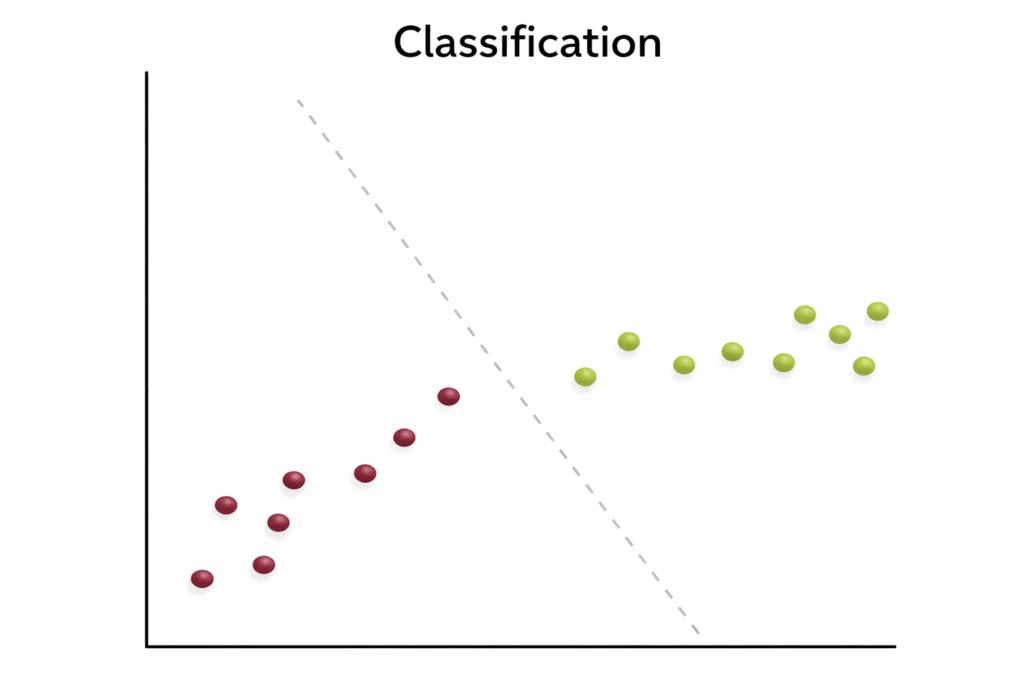
Output is discrete (like YES or NO, Cat or Dog, Pass or Fail).
Example:
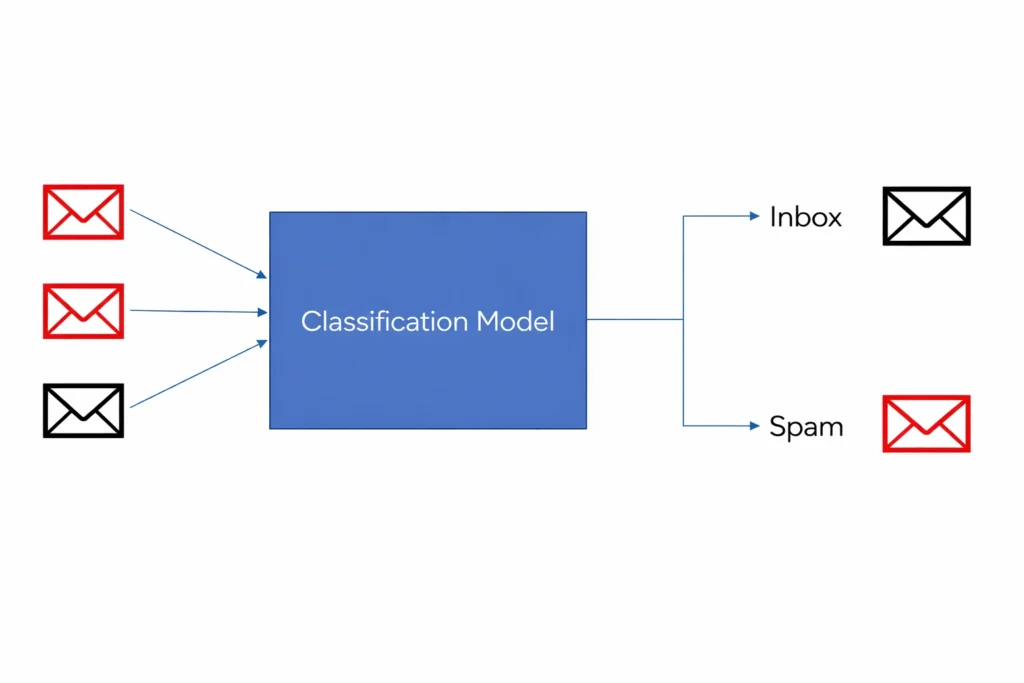
- Classifying wheather(????) todays weather(????️) is HOT or COLD
- Classifying emails as spam or not
Regression Model
Regression algorithms predict a continuous value based on the input variables. Continuous values as Temperature, Price, Income, Age, etc.
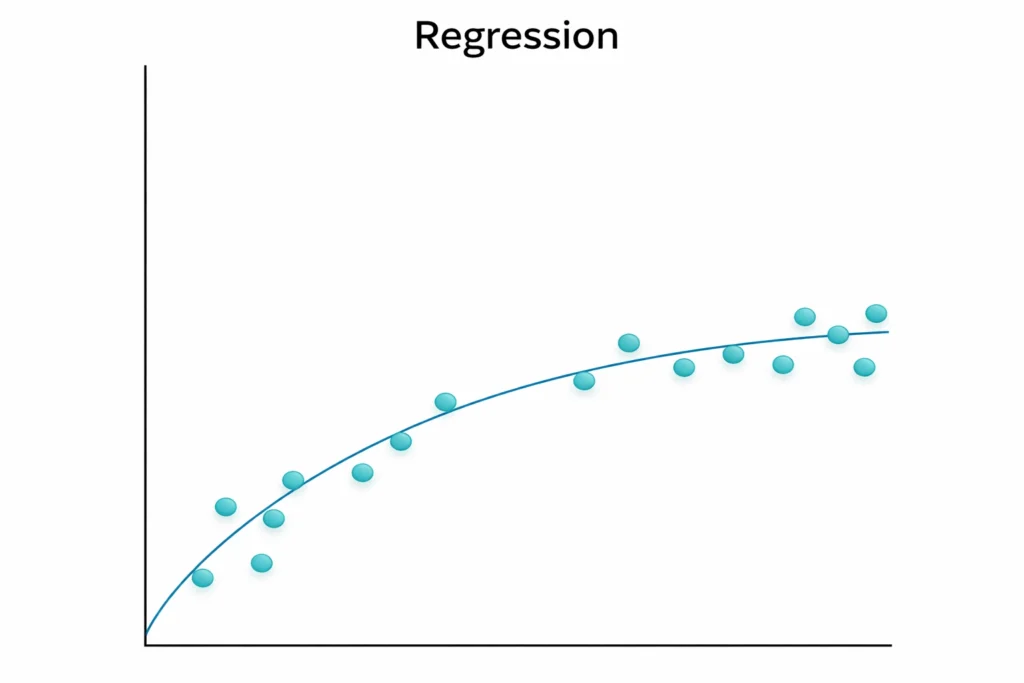
Example:
- Predicting temperature
- Predicting the price of the house
- Used Car Price Prediction
- Predicting salary

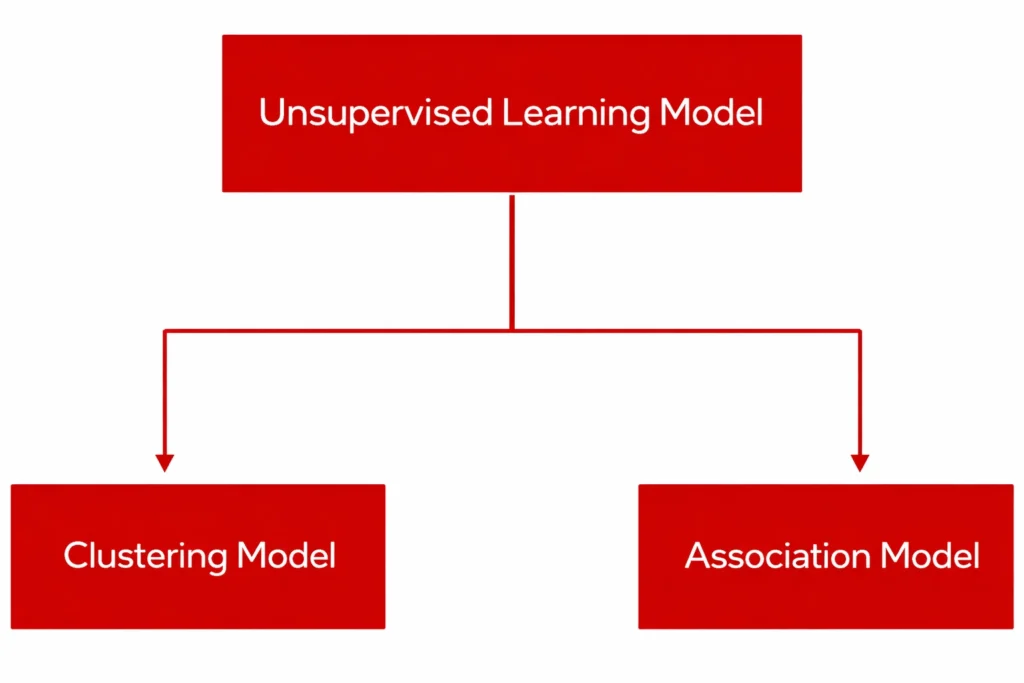
Sub-categories of Unsupervised Learning Model
Unsupervised learning models can be further divided into two categories: Clustering model and Association model.
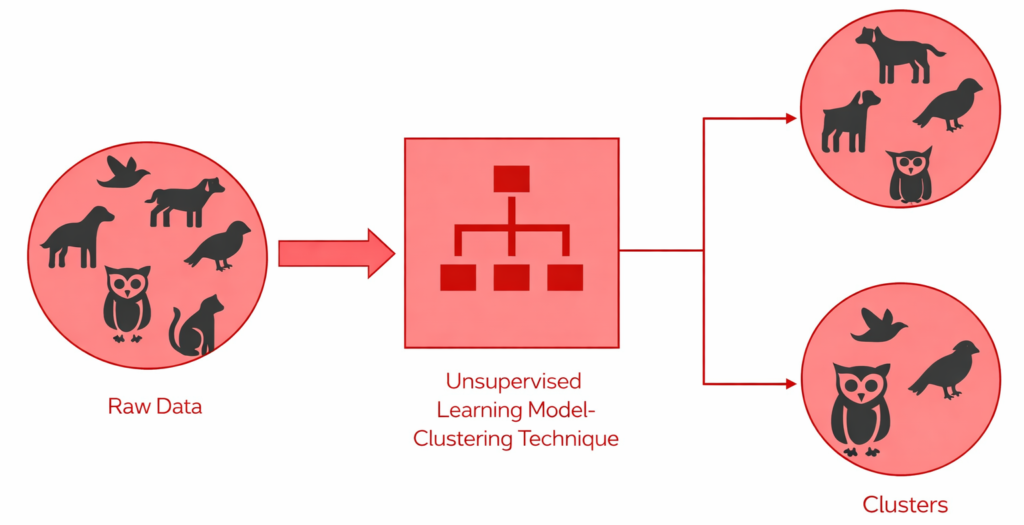
Clustering
Clustering is a process of dividing the data points into different groups or clusters based on their similarity between them.
Example: clusters based on likes and dislikes have been grouped together and given as output, such techniques are used in OTT platforms like Netflix/Spotify for recommendations.
Difference between Clustering and Classification
Clustering
- Unsupervised Learning technique (data is unlabeled).
- no predefined classes are given; the model groups data based on similarities.
- Clustering groups similar objects together to discover patterns (e.g., grouping customers based on buying behavior).
Classification
- Supervised Learning technique (data is labeled).
- predefined classes or categories are already given.
- Classification assigns objects to specific known categories (e.g., spam or not spam).
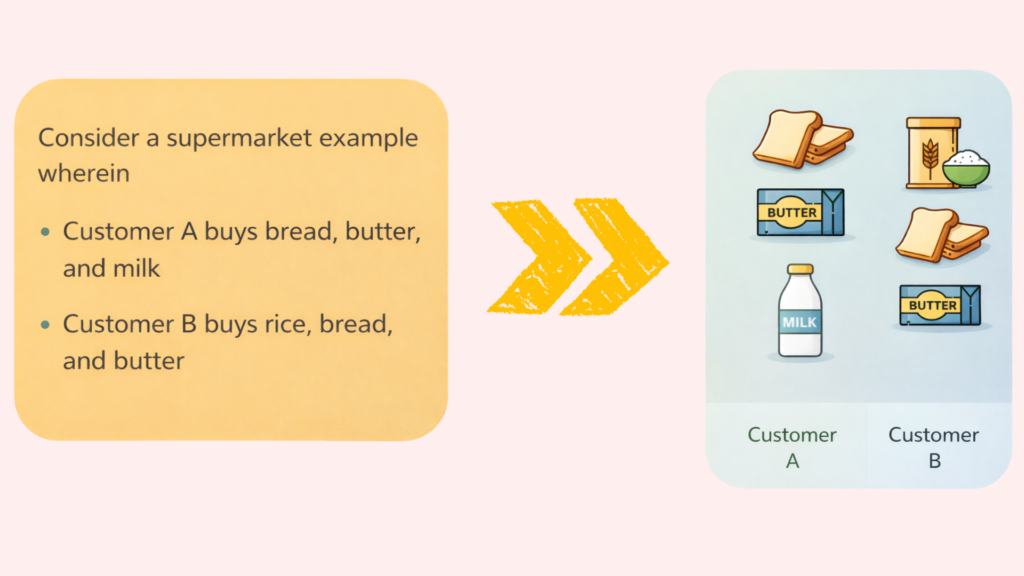
Association
Association Rule is an unsupervised learning method that is used to find interesting relationships between variables from the database.
Example:
- Based on the purchase pattern of customers A and B, can you predict any Customer X who buys bread will most probably buy?
- Based on the purchase pattern of other customers, we can predict that there is high probability that any customer x who buys bread will most probably buy butter.
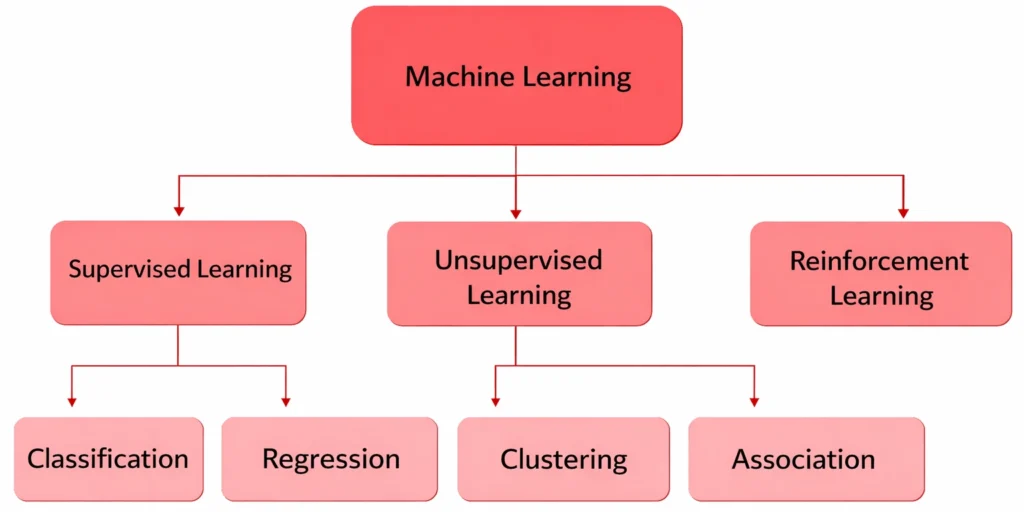
Summary of detailed classification of ML models
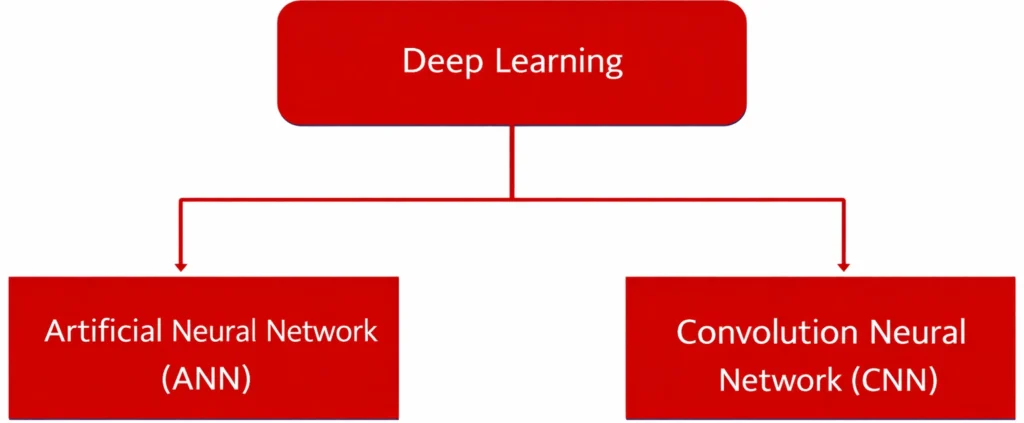
Sub-Categories of Deep Learning
Deep Learning enables software to train itself to perform tasks with vast amounts of data.
In deep learning, the machine is trained with huge amounts of data which helps it to train itself around the data. Such machines are intelligent enough to develop algorithms for themselves.
There are two types of Deep Learning models:
- Artificial Neural Networks (ANN)
- Convolution Neural Network (CNN).
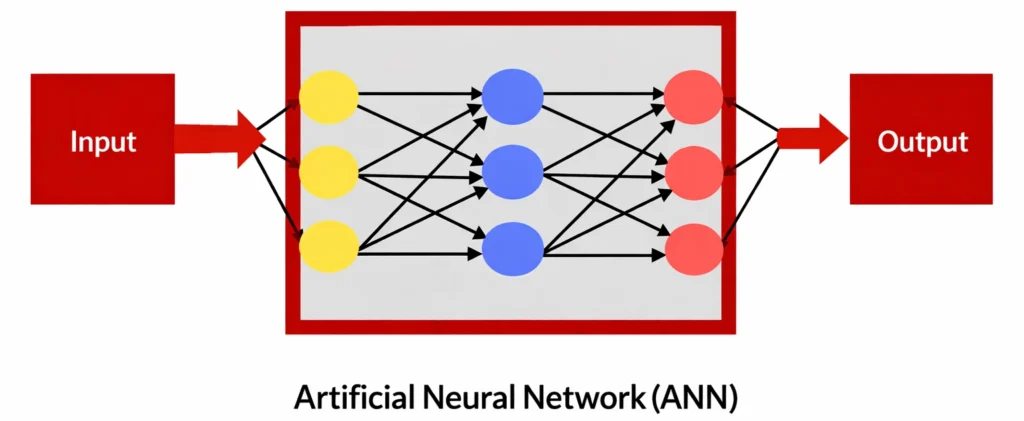
Artificial Neural networks (ANN)
- Artificial Neural networks are modelled on the human brain and nervous system.
- They are able to automatically extract features without input from the programmer.
- Every neural network node is essentially a machine learning algorithm.
- It is useful when solving problems for which the data set is very large.
Convolutional Neural Network (CNN)
- Convolutional Neural Network is a Deep Learning algorithm
- It can take in an input image, assign importance (learnable weights and biases) to various aspects/objects in the image and be able to differentiate one from the other
Artificial Neural Networks
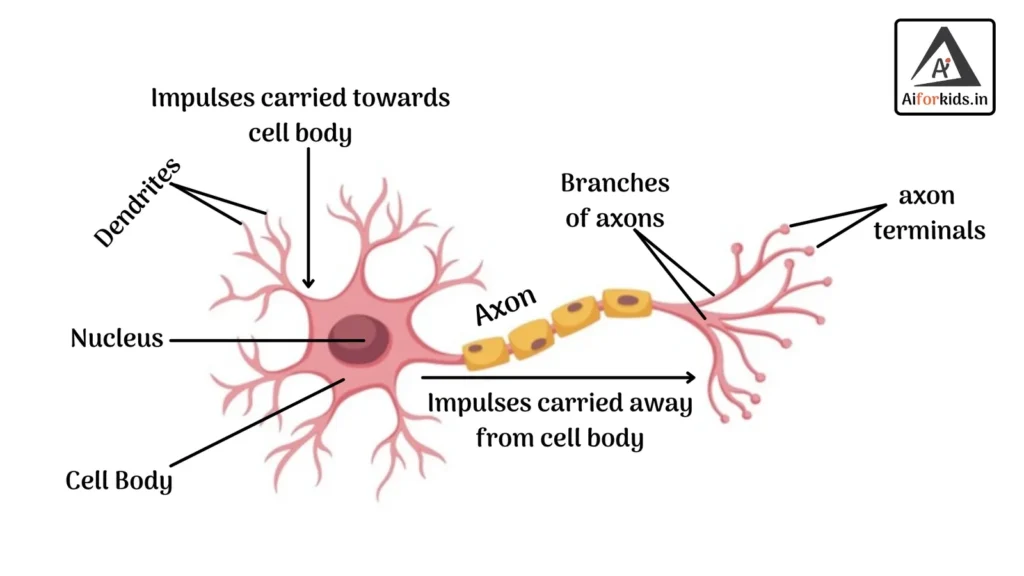
Neural networks are loosely modelled after how neurons in the human brain behave.
The key advantage of neural networks is that they are able to extract data features automatically without needing the input of the programmer.
A neural network is essentially a system of organising machine learning algorithms to perform certain tasks. It is a fast and efficient way to solve problems for which the data set is very large, such as in images.
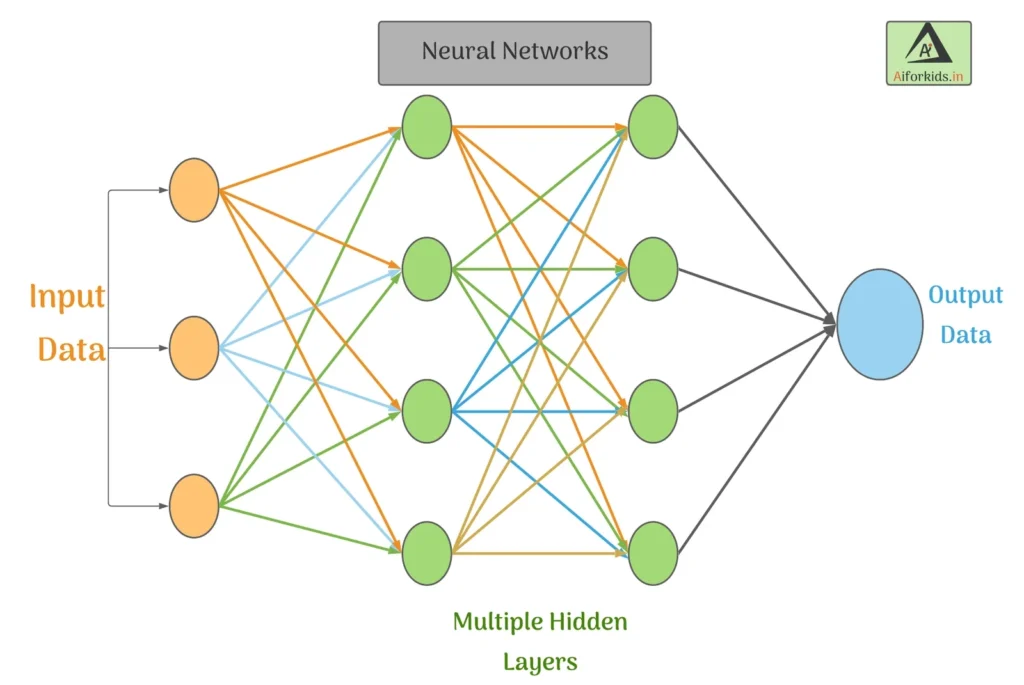
This is a representation of how neural networks work:
- A Neural Network is divided into multiple layers and each layer is further divided into several blocks called nodes. Each node has its own task to accomplish which is then passed to the next layer.
- Neural Network consists of an input layer, hidden layer which performs computation using weights and biases on each node and finally, information is passed through these layers to reach the output layer.
- The first layer of a Neural Network is known as the input layer. The job of an input layer is to acquire data and feed it to the Neural Network. No processing occurs at the input layer.
- Next to it, are the hidden layers. Hidden layers are the layers in which the whole processing occurs. Their name essentially means that these layers are hidden and are not visible to the user.
- Each node of these hidden layers has its own machine learning algorithm which it executes on the data received from the input layer.
- The hidden layer performs computation by means of weights and biases Information passes from one layer to the other after the value found from this calculation passed through a selected activation function.
- The process of finding the right output begins with trial and error until the network finally learns.
- With each try, the weights are adjusted based on the error found between the desired output and the network output.
Following is the representation of a neuron within a human body:
Perceptron
- Decisions depend on multiple factors
- Not all factors are equally important
Example:
- Inputs (X): Do I have a jacket?
- Do I have an umbrella?
- Is it sunny now?
- Weather forecast for later?
- Each input has a weight (importance)
- A bias (B) represents personal nature (cautious / daring)
Perceptron Working
- Convert Yes / No → 1 / 0
- Multiply inputs with weights
- Add all values + bias
- Compare with threshold
- Output > threshold → Yes
- Output ≤ threshold → No