
Computer Vision Glossary
Video Lecture on Computer Vision
Introduction to Computer Vision
Computer vision is a branch in the Domain of AI that enables computers to analyze meaningful information from images, videos, and other visual inputs.
Computer vision is the same as the human eye, It enables us see-through images or visual data, process and analyzes them on the basis of algorithms and methods in order to analyze actual phenomena with images.

AI enables computers to think, and computer vision enables AI to see, observe and make sense of visual data (like images & videos).
Computer Vision
- Computer vision deals with extracting information from the input images or videos to infer meaningful information and understanding them to predict the visual input.
- Computer Vision is a superset of Image Processing.
- Examples – Object detection, Handwriting recognition, etc.
Image Processing
- Image processing is mainly focused on processing the raw input images to enhance them or preparing them to do other tasks.
- Image Processing is a subset of Computer Vision.
- Examples – Rescaling image, Correcting brightness, Changing tones, etc.
Applications of Computer Vision
This decade and the upcoming one can witness a significant leap in technology that has put computer vision on the priority list. Some common uses of Computer Vision are:
Facial recognition
The most frequently used technology is smartphones. It is a technology to remember and verify a person, object, etc from the visuals from the given pre-defined data. Such kinds of mechanics are often used for security and safety purposes.
For eg: Face security lock-in devices and traffic cameras are some examples using facial recognition.
Facial filters
Modern days social media apps like Snapchat and Instagram use such kinds of technology that extract facial landmarks and process them using AI to get the best result
Goggle lens
To search data, Google uses Computer vision for capturing and analyzing different features of the input image to the database of images and then gives us the search.
Automotive
The machinery in industries is now using Computer vision. Automated cars are equipped with sensors and software which can detect the 360 degrees of movements determine the location, detect objects and establish the depth or dimensions of the virtual world.
For eg: Companies like Tesla are now interested in developing self-driving cars
Medical Imaging
For the last decades, computer vision medical imaging application has been a trustworthy help for physicians and doctors. It creates and analyzes images and helps doctors with their interpretation.
The application is used to read and convert 2D scan images into interactive 3D models.
Computer Vision Tasks
The Application of the computer is performed by certain tasks on the data or input provided by the user so it can process and analyze the situation and predict the outcome.
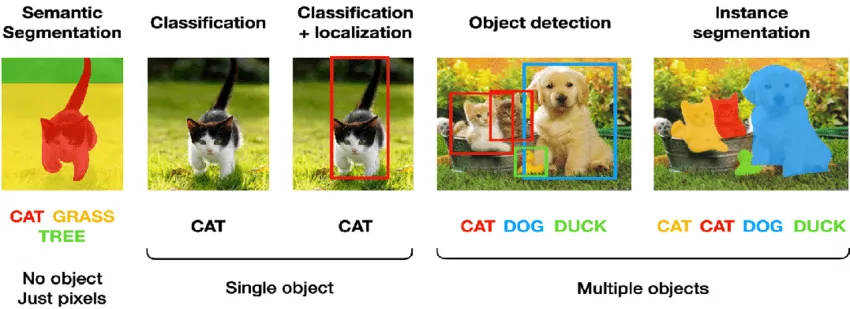
Single object
Image Classification
Image Classification is the task of identifying an object in the input image and label from a predefined category.
Classification + Localization
As the name suggests, the task identifies the object and locates it in the input image.
Multiple object
Object detection
Object detection tasks extract features from the input and use learned formulas to recognize instances of an object category.
Instance segmentation
Instance segmentation assigns a label to each pixel of the image. It is used for tasks such as counting the number of objects
Classification
The task of assigning an input image one label from a fixed set of categories.
This is one of the core problems in CV that, despite its simplicity, has a large variety of practical applications.
Classification + Localisation
This is the task that involves both processes of identifying what object is present in the image and, at the same time, identifying the location at which that object is present in that image. It is used only for single objects.
Object Detection
It is the process of finding instances of real-world objects such as faces, bicycles, and buildings in images or videos.
Object detection algorithms typically use extracted features and learning algorithms to recognize instances of an object category. It is commonly used in applications such as image retrieval and automated vehicle parking systems.
Instance Segmentation
Instance Segmentation is the process of detecting instances of the objects, giving them a category, and then giving each pixel a label based on that
A segmentation algorithm takes an image as input and outputs a collection of regions (or segments).
Basics of Images
The word “pixel” means a picture element.
Pixels
- Pixels are the fundamental element of a photograph.
- They are the smallest unit of information that make up a picture.
- They aretypically arranged in a 2-dimensional grid.
- In genral term, The more pixels you have, the more closely the image resembles the original.
Resolution
- The number of pixels covered in an image is sometimes called the resolution
- Term for area covered by the pixels in covectionally known as resolution.
- For eg :1080 x 720 pixels is a resolution giving numbers of pixels in width and height of that picture.
- A megapixel is a million pixels
Pixel value
- Pixel value represent the brightness of the pixel.
- The range of a pixel value in 0-255(2^8-1)
- where 0 is taken as Black or no colour and 255 is taken as white
Why do pixel values have numbers?
Computer systems only work in the form of ones and zeros or binary systems. Each bit in a computer system can have either a zero or a one. Each pixel uses 1 byte of an image each bit can have two possible values which tells us that the 8 bit can have 255 possibilities of values that start from 0 and ends at 255.
Grayscale Images
- Grayscale images are images which have a range of shades of gray without apparent colour. The lightest shade is white total presence of colour or 255 and darkest colour is black at 0.
- Intermerdiate shades of gray have equal brightness levels of the three primary colours RBG.
- The computers store the images we see in the form of these numbers.
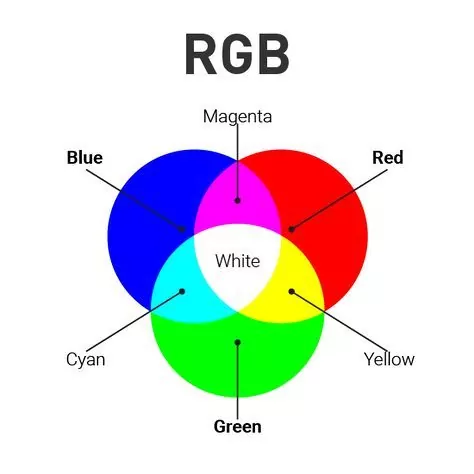
RBG colurs
- All the coloured images are made up of three primary colours Red, Green and Blue.
- All the other colour are formed by using these primary colours at different proportions.
- Computer stores RGB Images in three different channels called the R channel, G channel and the B channel.
Image Features
- A feature is a description of an image.
- Features are the specific structures in the image such as points, edges or objects.
- Other examples of features are related to tasks of CV motion in image sequences, or to shapes defined in terms of curves or boundaries between different image regions.
OpenCV or Open Source Computer Vision Library is that tool that helps a computer to extract these features from the images. It is capable of processing images and videos to identify objects, faces, or even handwriting.
2024 Syllabus is restricted till the portion covered above this note, the portion below will be assessed via Practicals Only!
Convolution
Convolutions are one of the most critical, fundamental building blocks in computer vision and image processing.
We learned that computers store images in numbers and that pixel are arranged in a particular manner to create the picture we can recognize. As we change the values of these pixels, the image changes.
Image convolution is simply an element-wise multiplication of two matrices followed by a sum. Convolution is using a ‘kernel’ to extract certain ‘features’ from an input image.
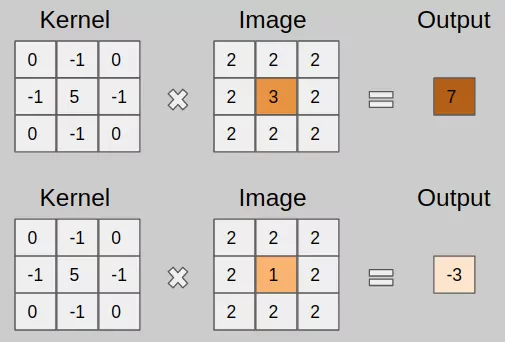
A kernel is a matrix or a small matrix used for blurring, sharpening, and many more which is slid across the image and multiplied with the input such that the output is enhanced in a certain desirable manner.
Now let’s see the steps of convolution :
- Take two matrices (Input Image +kernel with dimensions).
- Multiply them, element-by-element (i.e., not the dot-product, just a simple multiplication).
- Sum the elements together.
- Then the sum will be the certre value of the image.
Convolution Neural Network
CNN is an efficient recognition algorithm that is widely used in image recognition and processing that is specifically designed to process pixel data.
Convolution Layer
The first Convolution Layer is responsible for capturing the Low-Level features such as edges, color, gradient orientation, etc. In the convolution layer, there are several kernels that help us in processing the image further produce several features. The output of this layer is called the feature map.
For eg: If we consider it as a kid, we teach him the landmarks in the image, and then if he finds these similar landmarks in another he will identify that object same is the case with AI we use convolution for picking the landmark from the input for further editing.

Rectified Linear Unit Function
The next layer in the CNN is the Rectified Linear Unit function or the ReLU layer. This layer simply gets rid of all the negative numbers in the feature map and lets the positive number stay as it is. It has become the default activation function for many types of neural networks because a model that uses it is easier to train and often achieves better performance.
Pooling Layer
The Pooling layer is responsible for reducing the spatial size of the Convolved Feature while still retaining the important features. Image is more resistant to small transformations, distortions, and translations to the input image.
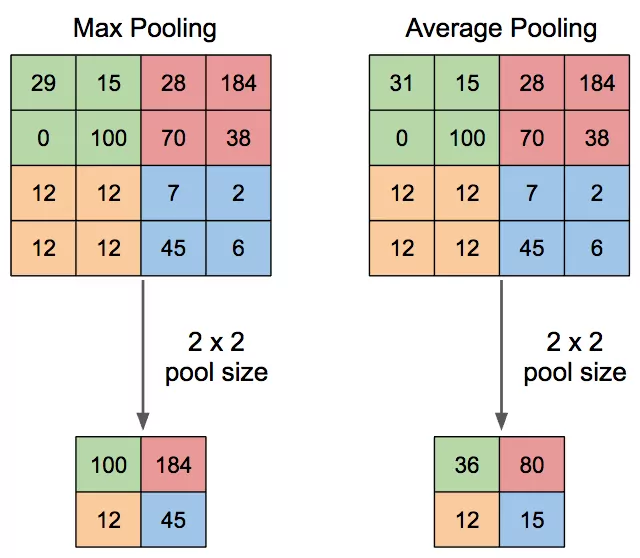
There are two types of pooling:
- Max pooling: The maximum pixel value of the batch is selected.
- Average pooling: The average value of all the pixels in the batch is selected.
What is the difference between convolution and pooling layer?
The major difference is if you include a large stride in the convolution filter, you are changing the types of features you extract in the algorithm, whereas if you change it in the pooling layer, you are simply changing how much the data is downsampled.
Fully Connected Layer
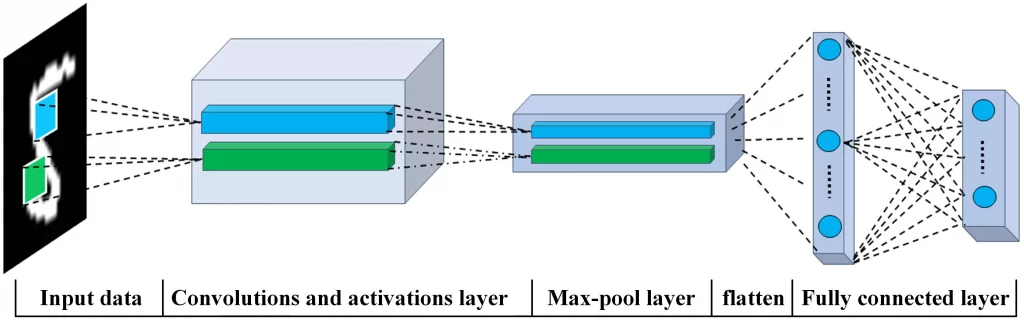
The final layer in the CNN is to connect all the dots and make a conclusion within the input and output of the image.
The output from the convolutional/pooling layers represents high-level features in the data. That output needs to be connected to the output layer, A fully-connected layer is a cheap way of learning non-linear combinations of these features.
For eg: if the image is of a cat, features representing things like whiskers or fur should have high probabilities for the label “cat”
To practically try how amazing Computer Vision works visit: Teachable machine
Related links
| Domain of AI | Data science |
| Ask Question | Class 10 Syllabus |