
Bag of Words is a popular Natural Language Processing (NLP) model used to extract important features from text. In machine learning, text data cannot be directly understood by algorithms. Therefore, we convert text into numerical form. The Bag of Words model helps in doing exactly that.
In simple terms, the Bag of Words model counts how many times each word appears in a given text. It creates a vocabulary of unique words and calculates their frequency in the corpus.
Thus, this gives us two main outputs:
- A vocabulary of words from the corpus
- The frequency of each word
This numerical representation of text is widely used in text classification, sentiment analysis, and spam detection.
Introduction to Bag of Words
The Bag of Words model is one of the simplest techniques in NLP for text feature extraction. It converts text into a structured numerical format so that machine learning algorithms can process it.
Instead of focusing on grammar or sentence structure, the Bag of Words model only focuses on:
- Unique words
- Number of occurrences of each word
Because of this simplicity, it is easy to implement and computationally efficient.
Why is it Called “Bag of Words”?
The term “Bag of Words” represents the idea that words are collected in a bag without caring about their order.
In this model:
- The sequence of words does not matter
- Grammar is ignored
- Only unique words and their counts are important
For example, the sentences:
- “I love AI”
- “AI love I”
will produce the same Bag of Words representation because they are same.
Therefore, the model treats text like a bag containing words, where position and order are not important.
How the Bag of Words Model Works?
This model follows a clear step-by-step process to convert text into numerical form.
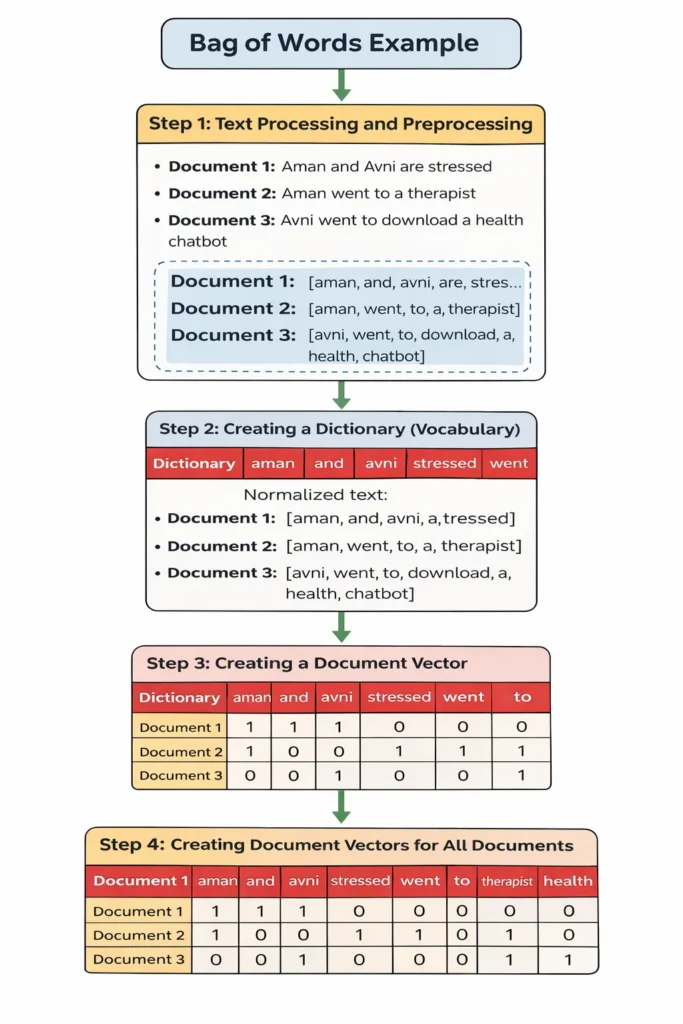
Step 1: Text Processing and Preprocessing
The first step is collecting the documents and cleaning the text.
Suppose we have three documents:
- Document 1: Aman and Avni are stressed
- Document 2: Aman went to a therapist
- Document 3: Avni went to download a health chatbot
Before applying the Bag of Words model, we normalize the text by:
- Converting all words to lowercase
- Removing punctuation
- Splitting sentences into tokens (words)
After normalization:
- Document 1: [aman, and, avni, are, stressed]
- Document 2: [aman, went, to, a, therapist]
- Document 3: [avni, went, to, download, a, health, chatbot]
This preprocessing ensures uniformity in the corpus.
Step 2: Creating a Dictionary (Vocabulary)
Next, we create a dictionary, also called the vocabulary.
We go through all documents and list down every unique word that appears. Even if a word is repeated in multiple documents, it is written only once in the dictionary.
From the example, the vocabulary becomes:
aman, and, avni, are, stressed, went, to, a, therapist, download, health, chatbot
This vocabulary represents all unique words in the corpus.
Step 3: Creating a Document Vector
In this step, we convert each document into a vector.
The vocabulary words are written as column headers. For each document:
- If a word appears in the document, assign 1
- If it does not appear, assign 0
For Document 1: Words present: aman, and, avni, are, stressed
So its vector representation becomes:
1 1 1 1 1 0 0 0 0 0 0 0
This means those five words are present, and the rest are absent.
Step 4: Creating Document Vectors for All Documents
Now, we repeat the same process for all documents.
The final result is a document-term matrix, where:
- The first row contains the vocabulary
- Each subsequent row represents one document
- 1 indicates presence of a word
- 0 indicates absence of a word
This matrix is the numerical representation of the text corpus.
It allows machine learning algorithms to process text data efficiently.
Understanding the Document-Term Matrix in Bag of Words
After completing Step 4, we obtain a document-term matrix. This matrix is the final output of the Bag of Words model.
In this table:
- The header row contains the vocabulary (unique words).
- Each row below represents one document.
- The numbers (0 and 1) show whether a word is present or absent in a document.
For example:
- If a word appears in a document → it gets 1
- If a word does not appear → it gets 0
Therefore, the entire text corpus is converted into numerical format.
This matrix is extremely important because machine learning algorithms cannot understand text directly, but they can understand numbers.
Output of the Bag of Words Model
This model produces two main outputs:
1. Vocabulary List
A list of all unique words in the corpus.
2. Document-Term Matrix
A numerical table showing the occurrence (or presence) of words in each document.
However, one limitation here is that all words are treated equally. The model only counts word occurrences and does not consider importance or meaning.
This leads to more advanced techniques such as TF-IDF, which improves word weighting.
Limitations of the Bag of Words Model
Although the Bag of Words model is simple and powerful, it has some limitations:
- Ignores Word Order
The model does not consider the position of words in a sentence.
- Ignores Context
It cannot understand the meaning of words. For example, “bank” (river bank) and “bank” (financial bank) are treated the same.
- High Dimensionality
If the corpus is large, the vocabulary size becomes very large, which increases computational complexity.
- Equal Importance to All Words
Common words may dominate the representation even if they are not important.
Because of these limitations, advanced models like TF-IDF and Word Embeddings are used in real-world NLP systems.
Applications of Bag of Words
Despite its simplicity, the Bag of Words model is widely used in many applications:
- Spam Detection – Identifying spam emails
- Sentiment Analysis – Determining positive or negative reviews
- Text Classification – Categorizing documents
- Chatbots – Basic intent recognition
- Search Engines – Matching keywords in documents
The Bag of Words model serves as a foundational step in Natural Language Processing and Machine Learning.