
NLP Class 10 Aritificial Intelligence CBSE conveys the connction between human langauges and machine processing.
Here we discuss about Applications of NLP, Chatbots, Text Classificaiton, NLP processes such as Text Normalization and Bag of words algorithm
Introduction to Natural Language
A natural language is a human language, such as French, Spanish, English, Japanese, etc
Features of Natural Languages:
- They are governed by set rules that include syntax, lexicon, and semantics.
- All natural languages are redundant, i.e., the information can be conveyed in multiple ways.
- All natural languages change over time.
What is NLP?
Natural Language Processing (NLP) is the sub-field of AI that focuses on the ability of a computer to understand human language (command) as spoken or written and to give an output by processing it, is called Natural Language Processing (NLP). It is a component of Artificial Intelligence.
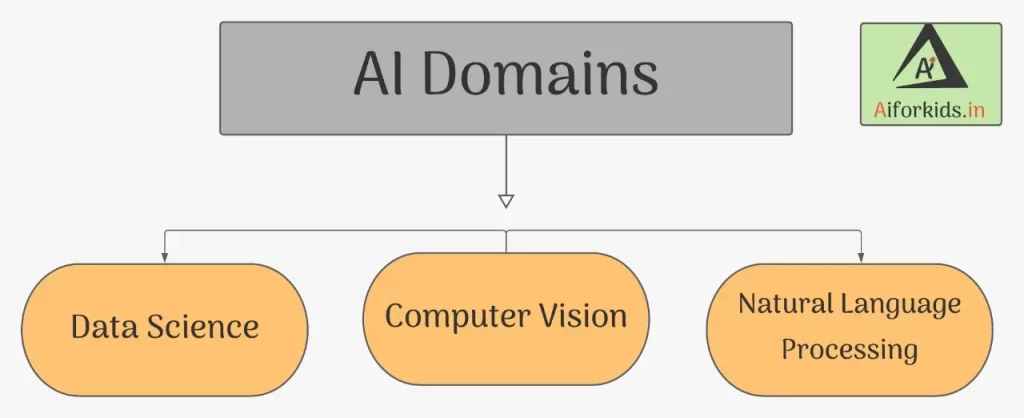
Till now we have covered two domains of AI that is Data Science & Computer vision and NLP is Third Domain of AI
- Data Science: It is all about applying mathematical and statistical principles to data or in simple words, Data Science is the study of Data, This data can be of 3 types – Audio, Visual and Textual.
- Computer Vision: In simple words is identifying the symbols from the given object (pictures) and learning the pattern and alert or predicting the future object using the camera.
Applications of NLP
Some of the applications of Natural Language Processing that are used in the real-life scenario:
Automatic Summarization
- Summarizing the meaning of documents and information
- Extract the key emotional information from the text to understand there actions (Social Media)
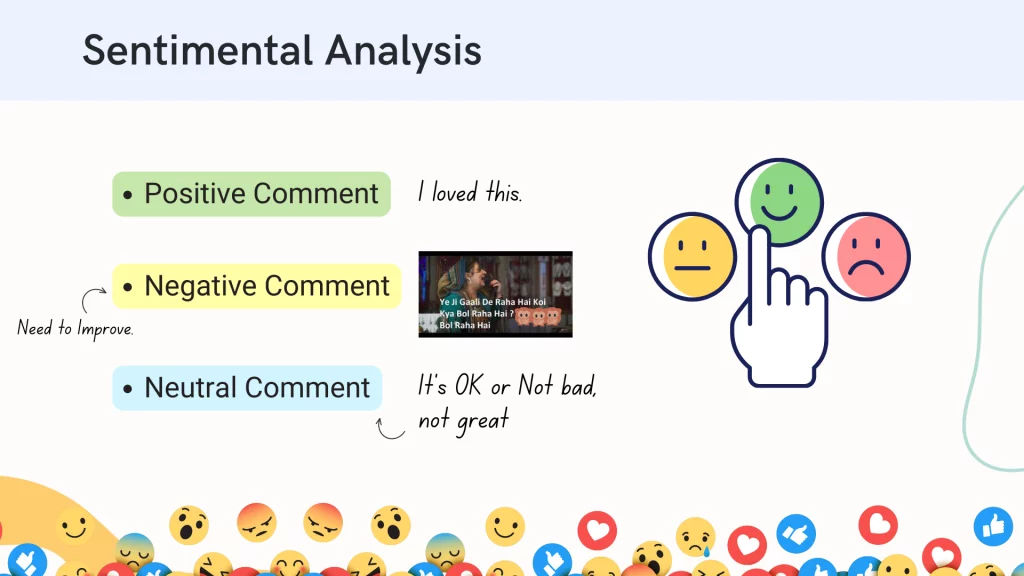
Sentiment Analysis
- Definition: Identify sentiment among several posts or even in the same post where emotion is not always explicitly expressed.
- Companies use it to identify opinions and sentiments to understand what customers think about their products and services.
- Can be Positive, Negative or Neutral
Text Classification
- Text classification makes it possible to assign predefined categories to a document and organize it to help you find the information you need or simplify some activities.
- For example, an application of text categorization is spam filtering in email.
Virtual Assistants
- Nowadays Google Assistant, Cortana, Siri, Alexa, etc have become an integral part of our lives. Not only can we talk to them but they also have the ability to make our lives easier.
- By accessing our data, they can help us in keeping notes of our tasks, making calls for us, sending messages, and a lot more.
- With the help of speech recognition, these assistants can not only detect our speech but can also make sense of it.
- According to recent research, a lot more advancements are expected in this field in the near future
Stages of Natural Language Processing (NLP)
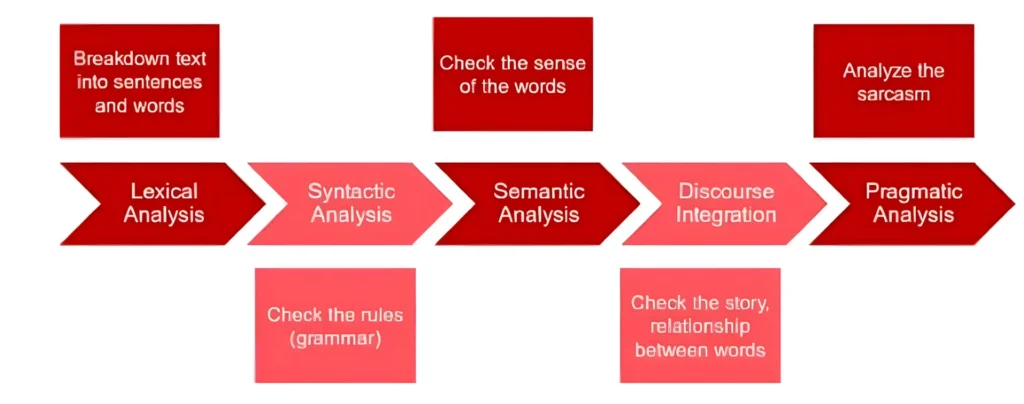
Lexical Analysis
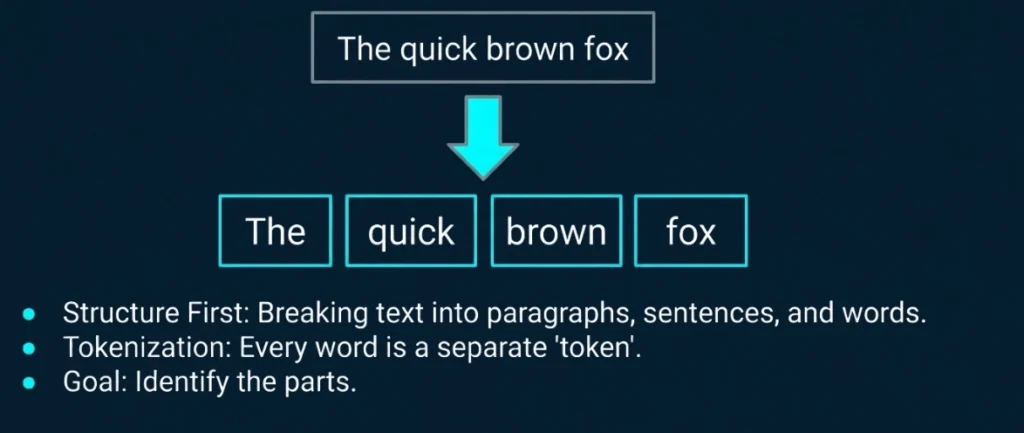
NLP starts with identifying the structure of input words. It is the process of dividing a large chunk of words into structural paragraphs, sentences, and words.
Lengthy text is broken down into chunks.
Lexicon stands for a collection of the various words and phrases used in a language
Syntactic Analysis / Parsing
It is the process of checking the grammar of sentences and phrases. It forms a relationship among words and eliminates logically incorrect sentences.
• The Grammar Check: Also known as Parsing.
• Rule Enforcement: Checking arrangement against language rules.
• Goal: Ensure the sentence is logically correct.

Semantic Analysis
In this stage, the input text is now checked for meaning, and every word and phrase is checked for meaningfulness.

- The Meaning Check: Do the words make sense together?
- Literal Interpretation: Checking for meaningfulness.
- Example: ‘Hot Ice Cream’ is REJECTED (Logically Impossible)
Discourse Integration
It is the process of forming the story of the sentence. Every sentence should have a relationship with its preceding and succeeding sentences.
- The ‘Story’ Mode: Connecting sentences.
- Context: Linking current sentence to the previous one.
- Goal: Understanding who ‘it, ‘he’, or ‘she’ refers to.

Pragmatic Analysis
In this stage, sentences are checked for their relevance in the real world. Pragmatic means practical or logical, i.e., this step requires knowledge of the intent in a sentence.
It also means to discard the actual word meaning taken after semantic analysis and take the intended meaning.

- Real-World Logic: Understanding intent over literal words.
- Challenge: Sarcasm, jokes, and metaphors.
- Example: ‘Pulling your leg’ means joking, not violence
Chatbots
One of the most common applications of Natural Language Processing is a chatbot. Let us try some of the chatbots and see how they work.

- Elizabot – https://www.masswerk.at/elizabot/

- Mitsuki – https://www.kuki.ai/

- Cleverbot – https://www.cleverbot.com/

- Singtel – https://www.singtel.com/personal/support
Types of Chatbots
With the help of this experience, we can understand that there are 2 types of chatbots around us: Script-bot and Smart-bot. Let us understand what each of
Script Bot
- Script bots are easy to make
- Script bots work around a script that is programmed in them
- Mostly they are free and are easy to integrate into a messaging platform
- No or little language processing skills
- Limited functionality
- Example: the bots which are deployed in the customer care section of various companies

Smart Bot
- Smart bots are flexible and powerful
- Smart bots work on bigger databases and other resources directly
- Smart bots learn with more data
- Coding is required to take this up on board
- Wide functionality
- Example: Google Assistant, Alexa, Cortana, Siri, etc.

Text Processing
As we have already gone through some of the complications in human languages above, now it is time to see how Natural Language Processing makes it possible for machines to understand and speak Natural Languages just like humans.
Since we all know that the language of computers is Numerical, the very first step that comes to our mind is to convert our language to numbers. This conversion takes a few steps to happen. The first step to it is Text Normalisation.
Text Normalisation helps in cleaning up the textual data in such a way that it comes down to a level where its complexity is lower than the actual data.
1. Text Normalisation
In-Text Normalization, we undergo several steps to normalize the text to a lower level. That is, we will be working on text from multiple documents and the term used for the whole textual data from all the documents altogether is known as corpus.
2. Sentence Segmentation
Under sentence segmentation, the whole corpus is divided into sentences. Each sentence is taken as a different data so now the whole corpus gets reduced to sentences.
Example:
Before Sentence Segmentation
“You want to see the dreams with close eyes and achieve them? They’ll remain dreams, look for AIMs and your eyes have to stay open for a change to be seen.”
After Sentence Segmentation
- You want to see the dreams with close eyes and achieve them?
- They’ll remain dreams, look for AIMs and your eyes have to stay open for a change to be seen.
3. Tokenisation
After segmenting the sentences, each sentence is then further divided into tokens. A “Token” is a term used for any word or number or special character occurring in a sentence.
Under Tokenisation, every word, number, and special character is considered separately and each of them is now a separate token.
Corpus: A corpus is a large and structured set of machine-readable texts that have been produced in a natural communicative setting.
OR
A corpus can be defined as a collection of text documents. It can be thought of as just a bunch of text files in a directory, often alongside many other directories of text files.
Example:
| 1. You want to see the dreams with close eyes and achieve them? | You | want | to | the | dreams | with | close | eyes | and | achieve | them | ? |
4. Removal of Stopwords
In this step, the tokens which are not necessary are removed from the token list. To make it easier for the computer to focus on meaningful terms, these words are removed.
Along with these words, a lot of times our corpus might have special characters and/or numbers.
Removal of special characters and/or numbers depends on the type of corpus that we are working on and whether we should keep them in it or not.
For example: if you are working on a document containing email IDs, then you might not want to remove the special characters and numbers whereas in some other textual data if these characters do not make sense, then you can remove them along with the stopwords.
Stopwords: Stopwords are the words that occur very frequently in the corpus but do not add any value to it.
Examples: a, an, and, are, as, for, it, is, into, in, if, on, or, such, the, there, to.
Example
- You want to see the dreams with close eyes and achieve them?
- the removed words would be
to,the,and,?
- The outcome would be:
- You want see dreams with close eyes achieve them
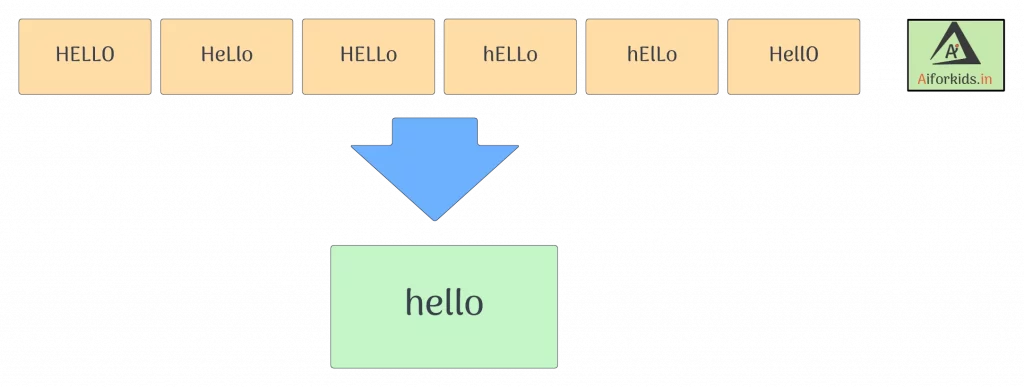
5. Converting text to a common case
As the name suggests, we e convert the whole text into a similar case, preferably lower case. This ensures that the case sensitivity of the machine does not consider the same words as different just because of different cases.
6. Stemming
Definition: Stemming is a technique used to extract the base form of the words by removing affixes from them. It is just like cutting down the branches of a tree to its stems.
The stemmed words (words which we get after removing the affixes) might not be meaningful.
Example:
| Words | Affixes | Stem |
|---|---|---|
| healing | ing | heal |
| dreams | s | dream |
| studies | es | studi |
7. Lemmatization
Definition: In lemmatization, the word we get after affix removal (also known as lemma) is a meaningful one and it takes a longer time to execute than stemming.
Lemmatization makes sure that a lemma is a word with meaning
Example:
| Words | Affixes | lemma |
|---|---|---|
| healing | ing | heal |
| dreams | s | dream |
| studies | es | study |
Difference between stemming and lemmatization
Stemming
- The stemmed words might not be meaningful.
- Caring ➔ Car
lemmatization
- The lemma word is a meaningful one.
- Caring ➔ Care
Bag of word Algorithm
Bag of Words is a Natural Language Processing model which helps in extracting features out of the text which can be helpful in machine learning algorithms. In a bag of words, we get the occurrences of each word and construct the vocabulary for the corpus.
Bag of Words just creates a set of vectors containing the count of word occurrences in the document (reviews). Bag of Words vectors is easy to interpret.
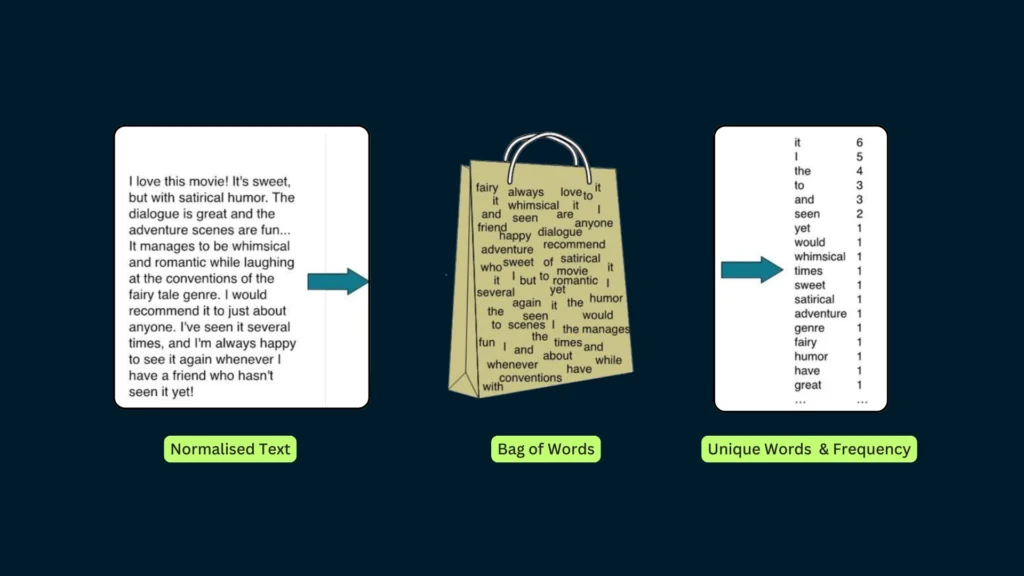
The text on the left in this image is the normalized corpus that we have got after going through all the steps of text processing. Now, as we put this text into the bag of words algorithm, the algorithm returns to us the unique words out of the corpus and their occurrences in it. As you can see at the right, it shows us a list of words appearing in the corpus, and the numbers corresponding to it show how many times the word has occurred in the text body.
The bag of words gives us two things:
- A vocabulary of words for the corpus
- The frequency of these words (number of times it has occurred in the whole corpus).
Here calling this algorithm a “bag” of words symbolizes that the sequence of sentences or tokens does not matter in this case as all we need are the unique words and their frequency in it.
Steps of the bag of words algorithm
- Text Normalisation: Collecting data and pre-processing it
- Create Dictionary: Making a list of all the unique words occurring in the corpus. (Vocabulary)
- Create document vectors: For each document in the corpus, find out how many times the word from the unique list of words has occurred.
- Create document vectors for all the documents.
Example:
Step 1: Collecting data and pre-processing it.
Raw Data
- Document 1: Aman and Anil are stressed
- Document 2: Aman went to a therapist
- Document 3: Anil went to download a health chatbot
Processed Data
- Document 1: [aman, and, anil, are, stressed ]
- Document 2: [aman, went, to, a, therapist]
- Document 3: [anil, went, to, download, a, health, chatbot]
Note that no tokens have been removed in the stopwords removal step. It is because we have very little data and since the frequency of all the words is almost the same, no word can be said to have lesser value than the other.
Step 2: Create Dictionary
Definition of Dictionary:
Dictionary in NLP means a list of all the unique words occurring in the corpus. If some words are repeated in different documents, they are all written just once while creating the dictionary. (Source: CBSE)
Dictionary:
| aman | and | anil | are | stressed | went |
| download | health | chatbot | therapist | a | to |
Some words are repeated in different documents, they are all written just once, while creating the dictionary, we create a list of unique words.
Step 3: Create a document vector
Definition of Document Vector: The document Vector contains the frequency of each word of the vocabulary in a particular document.
How to make a document vector table?
In the document, vector vocabulary is written in the top row. Now, for each word in the document, if it matches the vocabulary, put a 1 under it. If the same word appears again, increment the previous value by 1. And if the word does not occur in that document, put a 0 under it.
| aman | and | anil | are | stressed | went | to | a | therapist | download | health | chatbot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
step 4: Creating a document vector table for all documents
| aman | and | anil | are | stressed | went | to | a | therapist | download | health | chatbot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 |
In this table, the header row contains the vocabulary of the corpus and three rows correspond to three different documents. Take a look at this table and analyze the positioning of 0s and 1s in it.
Finally, this gives us the document vector table for our corpus. But the tokens have still not converted to numbers. This leads us to the final steps of our algorithm: TFIDF.
TFIDF
TFIDF stands for Term Frequency & Inverse Document Frequency.
Term Frequency
Term Frequency: Term frequency is the frequency of a word in one document.
Term frequency can easily be found in the document vector table in that table we mention the frequency of each word of the vocabulary in each document.
Example of Term Frequency:
| aman | and | anil | are | stressed | went | to | a | therapist | download | health | chatbot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 |
Here, as we can see that the frequency of each word for each document has been recorded in the table. These numbers are nothing but the Term Frequencies!
Inverse Document Frequency
To understand IDF (Inverse Document Frequency) we should understand DF (Document Frequency) first.
DF (Document Frequency)
Definition of Document Frequency (DF): Document Frequency is the number of documents in which the word occurs irrespective of how many times it has occurred in those documents. (Source: CBSE)
Example of Document Frequency:
| aman | and | anil | are | stressed | went | to | a | therapist | download | health | chatbot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 1 | 2 | 1 | 1 | 2 | 2 | 2 | 1 | 1 | 1 | 1 |
We can observe from the table is:
- Document frequency of ‘aman’, ‘anil’, ‘went’, ‘to’ and ‘a’ is 2 as they have occurred in two documents.
- Rest of them occurred in just one document hence the document frequency for them is one.
IDF (Inverse Document Frequency)
Definition of Inverse Document Frequency (IDF): In the case of inverse document frequency, we need to put the document frequency in the denominator while the total number of documents is the numerator.
Example of Inverse Document Frequency:
| aman | and | anil | are | stressed | went | to | a | therapist | download | health | chatbot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 3/2 | 3/1 | 3/2 | 3/1 | 3/1 | 3/2 | 3/2 | 3/2 | 3/1 | 3/1 | 3/1 | 3/1 |
Formula of TFIDF
The formula of TFIDF for any word W becomes:
TFIDF(W) = TF(W) * log( IDF(W) )
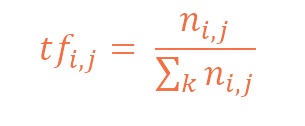
We don’t need to calculate the log values by ourselves. We simply have to use the log function in the calculator and find out!
Example of TFIDF:
| aman | and | anil | are | stressed | went | to | a | therapist | download | health | chatbot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1*log(3/2) | 1*log(3) | 1*log(3/2) | 1*log(3) | 1*log(3) | 0*log(3/2) | 0*log(3/2) | 0*log(3/2) | 0*log(3) | 0*log(3) | 0*log(3) | 0*log(3) |
| 1*log(3/2) | 0*log(3) | 0*log(3/2) | 0*log(3) | 0*log(3) | 1*log(3/2) | 1*log(3/2) | 1*log(3/2) | 1*log(3) | 0*log(3) | 0*log(3) | 0*log(3) |
| 0*log(3/2) | 0*log(3) | 1*log(3/2) | 0*log(3) | 0*log(3) | 1*log(3/2) | 1*log(3/2) | 1*log(3/2) | 0*log(3) | 1*log(3) | 1*log(3) | 1*log(3) |
Here, we can see that the IDF values for Aman in each row are the same and a similar pattern is followed for all the words in the vocabulary. After calculating all the values, we get:
| aman | and | anil | are | stressed | went | to | a | therapist | download | health | chatbot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.176 | 0.477 | 0.176 | 0.477 | 0.477 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.176 | 0 | 0 | 0 | 0 | 0.176 | 0.176 | 0.176 | 0.477 | 0 | 0 | 0 |
| 0 | 0 | 0.176 | 0 | 0 | 0.176 | 0.176 | 0.176 | 0 | 0.477 | 0.477 | 0.477 |
Finally, the words have been converted to numbers. These numbers are the values of each document. Here, we can see that since we have less amount of data, words like ‘are’ and ‘and’ also have a high value. But as the IDF value increases, the value of that word decreases. That is, for example:
- Total Number of documents: 10
- Number of documents in which ‘and’ occurs: 10
Therefore, IDF(and) = 10/10 = 1
Which means: log(1) = 0. Hence, the value of ‘and’ becomes 0.
On the other hand, the number of documents in which ‘pollution’ occurs: 3
IDF(pollution) = 10/3 = 3.3333…
This means log(3.3333) = 0.522; which shows that the word ‘pollution’ has considerable value in the corpus.
Important concepts to remember:
- Words that occur in all the documents with high term frequencies have the least values and are considered to be the stopwords.
- For a word to have a high TFIDF value, the word needs to have a high term frequency but less document frequency which shows that the word is important for one document but is not a common word for all documents.
- These values help the computer understand which words are to be considered while processing the natural language. The higher the value, the more important the word is for a given corpus.
Applications of TFIDF
TFIDF is commonly used in the Natural Language Processing domain. Some of its applications are:
- Document Classification – Helps in classifying the type and genre of a document.
- Topic Modelling – It helps in predicting the topic for a corpus.
- Information Retrieval System – To extract the important information out of a corpus.
- Stop word filtering – Helps in removing the unnecessary words from a text body.